AIが「考えない」ことを考える──「生成系AIが変える世界──『作家』は(/今度こそ)どこにいくのか」イベントレポート




2022年から2023年にかけて、Midjourney や ChatGPT などの生成系AIが登場し、世間の話題をさらった。清水は2022年9月にAI作画サービス「Memeplex」をいちはやく公開し、自身の note でAI画像のみを用いたマンガ作品を公開するなど、積極的な発信をおこなっている。生成系AIはどのような技術によってつくられ、わたしたちの世界をどう変えていくのか。計15時間にもわたる議論が展開された。
清水亮×さやわか×東浩紀「生成系AIが変える世界──『作家』はどこにいくのか」
URL= https://shirasu.io/t/genron/c/genron/p/20230210
清水亮×さやわか×東浩紀「生成系AIが変える世界2──『作家』は(今度こそ)どこにいくのか」
URL= https://shirasu.io/t/genron/c/genron/p/20230305
その趨勢を変えたのが生成系AIの登場だ。文章生成AIの ChatGPT は、人間味のあるレスポンスを返すのみならず、翻訳や文章構成を補助し、プロ並みのプログラミングコードすら生成するうえ、ほとんど誰もがそれを利用できる。いずれは本稿のようなレポートも、イベントの動画を生成系AIが読み込めば自動的にできあがってしまうのかもしれない(じっさいに、ゲンロン編集部では生成系AIを利用したイベントレポート作成の試みをすこしずつ始めている)。AIが人間のクリエイティビティや仕事をおびやかす兆しが具体的に見えつつある。この1年ほどで、AIがもたらす「世界革新」が急速にリアリティを獲得していった[★1]。
本レポートの執筆者は、言語人類学や記号論を専門とし、AI技術やその影響に注目してきた[★2]。技術革新は夢物語とともに語られがちだ。その夢物語に踊らされないためには、技術の持つ光と影をことばにして示す必要がある。ここで取り上げるイベントは、まさに生成系AIをめぐる技術的革新の内実を言語化するものだった。
生成系AIの技術──Deep Learning、Transformer、Stable Diffusion
2回をとおし、イベントは清水による講義を中心に進んだ。その内容は「講義」や「プレゼン」という言葉から連想される退屈さとはまったく無縁だった。東浩紀がよく言うように「AIに雑談はできない」。3人の語りには人間だからこそできる雑談の面白さが存分に発揮されている。特に Uber Eats 配達員をしているという清水亮が初回冒頭から繰り広げた、アツい「Uber Eats 攻略法」には腹が痛くなるほど笑わせられた。楽しく語る登壇者のやりとりをぜひ見てほしい(じつはこの Uber Eats の話題はある伏線になっているのだが、それが回収されるのは第2回の最後の最後である)。 
清水はイベントをとおし、わかりやすい比喩や例をまじえてAI技術を解説していく。その内容は実に濃く、それを聞くのはまるで知的な筋トレをするかのような体験だった。そこには人文知、情報技術、その社会的影響といった論点が交叉しており、キーワードも多岐にわたる。本レポートでは、イベントで解説された、Deep Learning 、Transformer 、Stable Diffusion の3つを軸に、AIの技術モデルの要点をまとめよう。
Deep Learning から間接民主主義を考える
まずは、AI開発の流れに関する基本を確認しておこう[★3]。2000年代後半から現在に至る流行は「第3次AIブーム」と呼ばれる。これは1950年代後半から1960年代の第1次AIブーム(「推論・探索」が中心)、1980年代から1990年代前半の第2次AIブーム(「知識」のインプットが中心)に続くものだ。では、それらと第3次AIブームのあいだにはどのような技術的ブレイクスルーがあったのか。それこそが、AI自身が画像や文章の特徴を学習する Deep Learning の登場である。
それまでのAIは、人間がデータを整備しその特徴を設定していた。その仕事がAIそのものによる「学習」に置き換わったわけだ(皮肉なことだが、AIの進歩によって旧来のAI研究者の仕事がいち早くなくなった)。
ここでいう学習とは、データを特徴的なパターン(「特徴量」)へと分けることを意味する。人間は多くの場合、特徴のパターンを組み合わせて物事を認知する。たとえば「チェックシャツ」を着て、「デニム」に「黒いリュック」を背負っている「メガネ」をかけた「男性」といえば「オタク」と(一昔前には)認識されたように。それと同じことを機械にさせるのが「学習」だ。それは技術的には、生物の神経細胞を機械で真似た人工ニューラルネットワークによって実現されている。
清水によれば、じつは人工ニューラルネットワークそのものは、1960年代の第1次AIブームでも考案されていたという。しかしそれは、「2010年代に入るまではバカにされていた」。データによって機械独自の知能を根拠づけるのではなく、生命のマネをするという「志が低い」発想であるからだ。しかし、清水はむしろそれゆえにこのアイディアが好きなのだという。 

では、このパーセプトロンの学習を高度にするにはどうしたらよいのか。一見すると中間層を増やせばより複雑な情報を処理できると思うかもしれない。じっさいAI研究の初期には、中間層を増やすことがブレイクスルーをもたらすと考えられた。しかしある段階からは、いくら中間層を増やしても学習レベルは上がらなかった。さまざまな重みづけによってノイズが増えてしまうだけだったのだ。
こちらは清水によれば、「間接民主制」を例にするとわかりやすい。いま日本の国民のなかで、「自分が岸田首相を選んだ」と考えている人は稀だろう。それは個々人の投票とその結果とのあいだのプロセスがあまりに多いからだ。同じようにパーセプトロンにおいても、中間層が増えると結局は最後の中間層と出力層だけが重要になり、入力されたデータを学習する効率が落ちてしまうのである。これを「勾配消失問題」と呼ぶ。

東は清水のこの解説に「これは代理は1回しかしちゃいけない問題だ」と議論をつなげた。日本では選挙と代表選という2回の代理を経て首相を選ぶ。しかし、国民一人ひとりの責任観を希薄化させないようにするには、1回の代理で代表者を選んだほうがいい。AIの技術モデルを政治思想のことばで置き換える、まさにゲンロンカフェのテーマ「文理融合」が実現された瞬間だった。

ChatGPT を支える Transformer の革新性
以上が第3次AIブームの火付け役となった Deep Learning の基本的な仕組みだが、いま流行の ChatGPT で用いられるのは Transformer というまた別の技術である。この Transformer の革新性は、文字から文字への変換を、統計や文法に基づかずに行う点だ。どういうことか。
Transformer の名前は「変換する transform」に由来する。具体的にはある行列を別の行列へと変換することを指している。ここでいう「行列」とはひとつの連なりではなく、「行」と「列」、すなわち縦と横に数字が並んだ平面を意味する。AIにある文章を読み込ませるためには、それをコンピューターが理解できる0と1の行列に置き換えることが必要なのだ。この作業を「埋め込み embedding」という。
補助線を引こう。たとえば “pen” という単語は、26個あるアルファベットのうち16番目の文字と、5番目の文字と、13番目の文字で構成されている。これらを数列に置き換えると、“p” は26桁のうち16桁目だけが1で他が0の数列として、“e” は5桁目だけが1で他が0の数列として、“n” は13桁目だけが1で他が0の数列として表現できる。つまり “pen” 全体は、
00000000000000010000000000
00001000000000000000000000
00000000000010000000000000
という行列に置き換えることができる。
embedding はこれと同じ操作を、単語ではなく文章のレベルで行う。下図の “I have a pen” という文字列を例に取ろう。まずは “I” を、AIが学習したすべての単語(便宜的に1024個とする)のうち4番目の語だと仮定する(数字は任意)。すると “I” は、「1024桁のうち4桁目だけが1でのこりが0」という数列に置き換えられる。おなじように “have” を8番目の、“a” を17番目の、“pen” を23番目の語として設定すると、“I have a pen” は4つの桁(1行目の4桁目、2行目の8桁目、3行目の17桁目、4行目の23桁目)だけが1で、ほかのすべてが0で構成された4行×1024列の行列に置き換えられる。この操作を行えばあらゆる文章は0と1の行列へと変換でき、したがって人工ニューラルネットワークに入力して機械学習をおこなうことができるわけだ。 
これをふまえたうえで Transformer の原理を説明しよう。さきほども述べたとおり、Transformer は行列を別の行列へと変換するモデルである。 
ここで重要なのが Transformer の Attention という特質だ。これは文章を生成する上で注目すべき場所をAIが判断することを意味する。たとえば「日本経済新聞」という語を予測するうえで、「日本」に注目しても続く単語は特定しづらい。しかし「本経」という部分に注目すれば、つぎは「経済」である可能性が高いだろう。
ここでは便宜的に文章を単語に区切って説明してきたが、AIが文章をどこで分節しどこに注目するかは、膨大な計算によって処理されるため、単語や文法や統計には縛られない。それはもはや人間には理解できないのだと清水は語った。
これは言い換えれば、Transformer では生成する文章が、単語のコーパスや文法によって規定されるわけではないということである。従来の機械学習ではそれら人間が設定できるデータをモデルにしてきたため、学習される特徴量の総体は限られていた。一方 Transformer では特徴量の抽出自体が計算(0と1からなる行列同士の、Attention に基づく比較)によって行われるため、無限に学習ができるのだ。そこでは単語や文法といった人間的な基準は考慮されない。幼稚園児が主語や述語を考えずにことばを学んでいくのと同じように、Transformer もただ文字の連なりだけから注目ポイントを学習していく。

ところでこの発想には、20世紀以来主流となってきた言語理論を揺るがすインパクトがある。実際シラスのコメントでも、今後の言語学者の役割について疑問の声があがった。イベントからは脱線するが、言語人類学を学ぶものとして、言語学とAIの関係について少し付記したい。
筆者としては、文法を考えない Transformer のメカニズムが成果をあげたことには納得がいった。人間の言語使用についての調査によれば、言語の構造の変化にも Transformer で扱うような予測(類推)と不可避のズレがはたらいているからだ[★4]。これは従来の言語理論が考慮に入れてこなかった発想だった。
人間は会話において文法規則を細かく意識しないが、一方で、めちゃくちゃな物言いばかりでは話は通じない。したがって規則的な文法構造とそこからのズレの両方を考慮に入れないと、言語のメカニズムは捉えきれない。文法を考慮しない Transformer が文章生成AIにおいて成果を発揮した事実は、言語理論にズレを考慮に入れた類推のメカニズムを取り込むことの意義を逆照射してくれている。
20世紀の言語学に大きな影響を与えた生成文法の祖であるノーム・チョムスキーは、ハンナ・アーレントの言葉を引いて、ChatGPT は「凡庸な悪(banality of evil)」だと表現している[★5]。知性を持たずデータによって予測するだけの ChatGPT を、命令されたという理由だけでユダヤ人を虐殺したアイヒマンになぞらえたのだ。
私見では、チョムスキーの指摘は一定程度正しい。だがその正しさは、近代言語学のパラダイムを牽引した彼の理性主義的イデオロギーと不可分だろう[★6]。確かに ChatGPT はぼくら人間と同じ知性を有しているわけではない。しかし他方で、その技術モデルである Transformer は、人間が他者のことばからの類推で学習していく姿を擬似的に教えてもくれる。清水は「考えない」ことこそがAIのポイントだと指摘している。そして人間は「考えない」ものからも考えることができるのだ。
ノイズから無限の「絵」を生成する Stable Diffusion
ここまで見てきた Deep Learning や Transformer といった第3次AIブームを支える技術は、近代的・理性的な「知能」のイメージとは異なる、人間の動物的側面に近いモデルを用いていた。最後に紹介する画像生成AI Stable Diffusion もまた、同じくシンプルな発想によって作られている。
しかしその内実はかなり異なる。Transformer は、インプットされた行列から続く行列を予測するものだった。それはいわば予測によってデータの辻褄を合わせるモデルだ。一方 Stable Diffusion で使われる「拡散 Diffusion」モデルは、元データにあえてノイズを増やし、そこからもとの画像に復元する、という方法で特徴量を学習する。それを繰り返し行うことで、傍目にはノイズにしか見えないデータから、無数の画像を生成できるようになる。 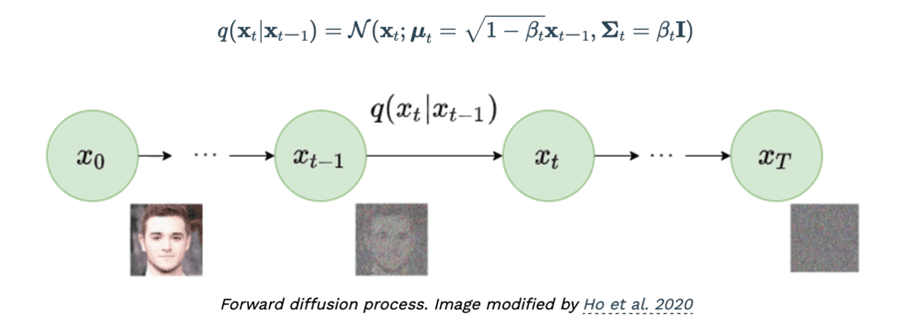
Transformer とはまったく異なるこのパラダイムこそ、 Stable Diffusion がエンジニアに衝撃を与えた理由だと清水は力説する。Transformer は、莫大な行列同士の対応関係を学習させるためデータ容量が多く、そのぶんサーバーの維持費や電気代がかかる。一方 Stable Diffusion はひとつのデータから特徴量を抽出できるため、圧倒的に燃費がいい。清水はつぎのように語る。
「Transformer モデルのデータやコードをいくらオープン化しても、数億円もするようなスパコンがなければ動かせなかった。Stable Diffusion は一般のパソコンでも動かせるものをオープン化した。だから、Stable Diffusion が公開されたときはみんな大騒ぎになったわけですよ」
イベントでは実際の画像を交えて Stable Diffusion の技術が紹介された。東はノイズから画像が生成される様子に驚きつつも、そのモデルを「画家や彫刻家が、白いキャンパスや木から『なにかが見えてくる』と言うような、人間のクリエイションに近い」と指摘する。
一方でひらめき☆マンガ教室の主任講師であるさやわかは、マンガのコマ割りを例に出す。コマ割りは一般的に、「単なる枠、もしくはマンガの文法に基づく配置」として捉えられている。しかし実際には、マンガ家は「ページ全体のなかのテンポのようなものとしてコマを浮かびあがらせて」おり、それは Stable Diffusion が行っていることにかなり近い。いまは「絵と文法の組み合わせ」としてマンガを捉えているからうまくいっていないだけで、マンガのAI生成も十分に可能だろう、と。

このように Stable Diffusion は、人間に「クリエイティビティとはなにか」という問いを投げかける。だが、問いはそれだけでは終わらない。清水はさらに「Transformer には生成できて、Stable Diffusion にはできないものとはなにか」という出題を聴衆に向けて行なった。Diffusion モデルは、音楽、画像、映像すらも生成することできる。ここに足りないものとはなにか?
じつは Diffusion モデルでは、文章が生成できない。AIはすべてのデータを0と1の行列に変換する以上、画像と文章の間に差異はないようにも思える。にもかかわらず、なぜ Diffusion モデルは文章が生成できないのか──その理由は一連のイベントのハイライトにあたる。ぜひアーカイブ動画を視聴してみてほしい。
その解答に驚嘆を禁じえない東とさやわかに対し、清水は「メディアの騒ぎに踊らされず、なぜ Diffusion モデルで文章が生成できないのか、その原理をまじめに考えてほしい」と語りかけた。その姿には、もはや Uber Eats 配達員の面影はなかった。
おわりに
計15時間にも及んだ議論のうち、今回のイベントレポートでまとめたのはあくまでも Deep Learning、Transformer、Stable Diffusion を軸とした講義の概要である。ほかにも、生成系AIと著作権の関係や、 ChatGPT ブームに先立って世間を席捲したNFTの問題点、あるいは清水がAI画像をもとに作成したマンガ「五反田三郎」についてなど、取り上げられなかった論点は枚挙に暇がない。なにより本記事では、イベントのタイトルにある「『作家』はどこにいくのか?」という問いへの登壇者らの応答には触れていない。そちらは第2回で展開されているので、動画をご覧いただきたい。
両イベントは、2010年代以降の第3次AIブームの系譜をたどりその意味を考えるだけでなく、そこからさらに思考を展開するきっかけが得られるものだった。筆者は技術的なブレイクスルーをもたらすのはごく単純な発想であり、それを阻害するのは既存の思い込みであること、そしてしばしば無意識的なその思い込みを訂正するのがとても難しいことを、AIや言語学の系譜を重ねながらつい考えてしまった。機械と人間のインターフェースをどう読み解き、どう語り直すのか。それこそがAIが考えないことなのかもしれない。(青山俊之) 
★1 画像生成AI Stable Diffusion がオープン化されたことをきっかけに、note社のCXO深津貴之が「世界変革の前夜は思ったより静か」(2022年8月22日、URL= https://note.com/fladdict/n/n13c1413c40de)という記事を公開している。清水も IT Media にて「清水亮の『世界を変えるAI』」と題した連載をしており、最初の記事は「まさに『世界変革』──この2ヶ月で画像生成AIに何が起きたのか」(URL= https://www.itmedia.co.jp/news/articles/2210/25/news158.html)となっている。
★2 筆者は人工知能研究者の大澤博隆の紹介で、2017年10月に開催された「Ai and Society」というシンポジウムのセッションのひとつを担当し、レポートを執筆したことがある。拙稿「今考えるべき問題と社会へのインパクト(懸念と期待)」、『人工知能学会誌』Vol. 33 No. 2、205-209頁。 なお大澤は1月にゲンロンカフェにも登壇している(URL= https://shirasu.io/t/genron/c/genron/p/20230106)。併せて視聴されたい。
★3 AIブームの歴史と各特徴についての記述は以下に拠った。松尾豊『人工知能は人間を超えるか ディープラーニングの先にあるもの』、角川EPUB選書、2015年。
★4 より具体的には、Transformer は言語の詩的機能(poetic function)と親和性が高いと思われる。ローマン・ヤコブソンが「等価性の原理を選択の軸から結合の軸に投射する」と定義した詩的機能は、音・文字・行為といったさまざまなレベルの反復によってメッセージが強調されるメカニズムを捉えた概念である。無数の記号列、記号生成、強調のメカニズムを扱うその議論は、無数の行列をべつの行列に変換し、注目点を学習する Transformer の発想と似ていると言えるだろう。拙稿「詩的機能──定義とその人類学的意味」(2023 年 6月 5 日、URL= https://www.turetiru.com/entry/poetic-function/)も参照されたい。
★5 Noam Chomsky “The False Promise of ChatGPT," The NewYork Times, 08/03/2023.(URL= https://www.nytimes.com/2023/03/08/opinion/noam-chomsky-chatgpt-ai.html)
★6 言語と人々の無/意識の関係を扱う議論を言語イデオロギー論という。言語に関するあらゆる考え方の背後にはイデオロギーがある。たとえば有名なシャノンとウィーバーのコミュニケーションモデルは、個人間の契約のように言語を捉えるイデオロギーとして知られる。その情報伝達モデルは西洋的・近代的で個人主義的な自己像を背景に成立した生成文法とも近しい。拙稿「言語イデオロギー論の射程──社会記号論系言語人類学の要」(2023年1月23日、URL=https://www.turetiru.com/entry/language-ideology/)も参照されたい。
URL= https://shirasu.io/t/genron/c/genron/p/20230210
清水亮×さやわか×東浩紀「生成系AIが変える世界2──『作家』は(今度こそ)どこにいくのか」
URL=https://shirasu.io/t/genron/c/genron/p/20230305
※好評につき、視聴期限を2024年9月30日まで延長しました。(2024.1.15更新)





